AI 에이전트 운영과 개발 플랫폼 업데이트 #39

오늘의 레터
- GitHub, 실패한 Actions용 Copilot 수정 기능 확대
- AWS, SageMaker JumpStart에 Nemotron 3 Ultra 추가
- NVIDIA·Microsoft, 윈도우용 로컬 AI 에이전트 도구 발표
- Cloudflare, AI Gateway 지출 제한 베타 공개
GitHub, 실패한 Actions용 Copilot 수정 기능 확대
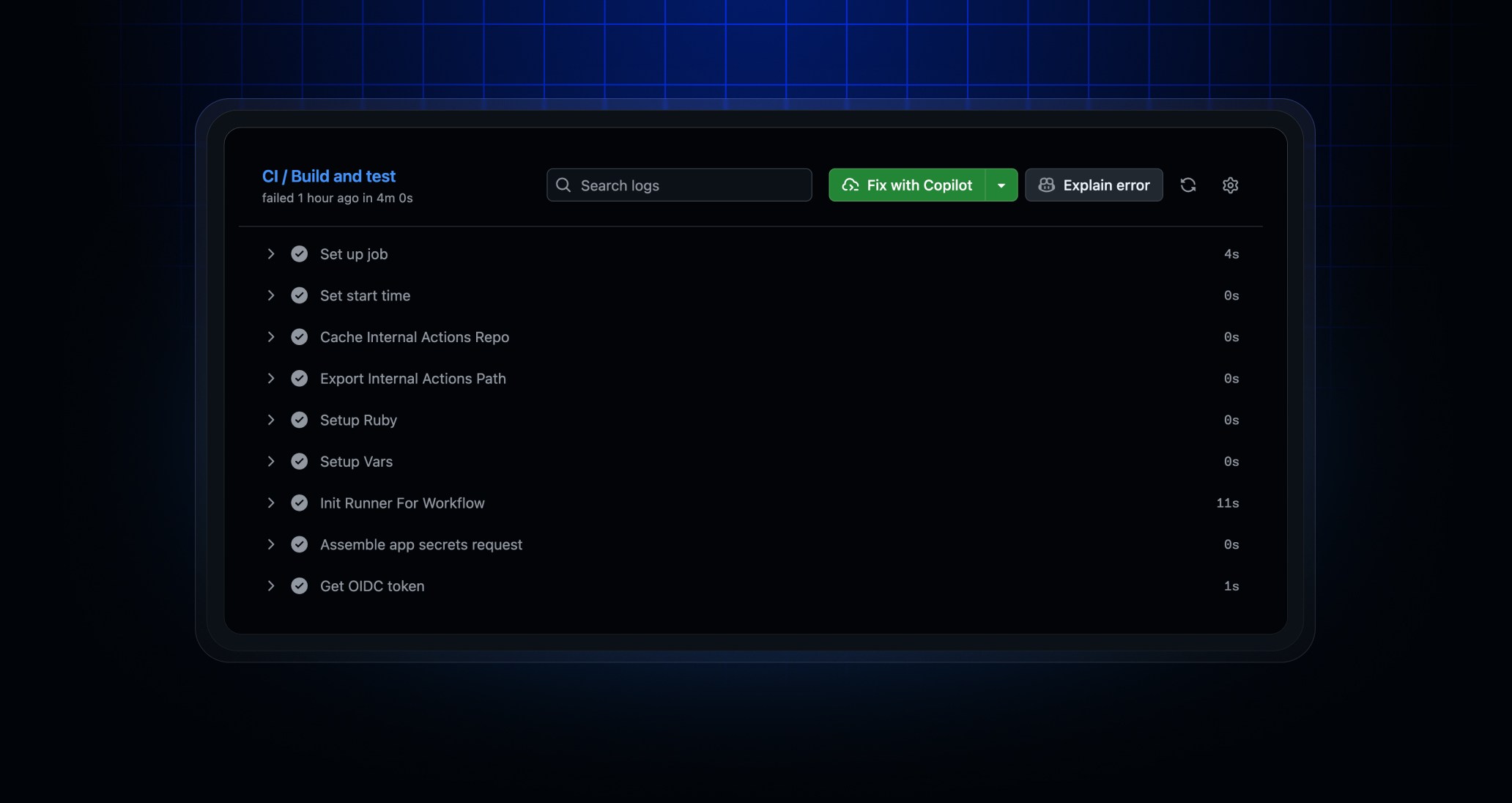
- GitHub이 실패한 GitHub Actions 작업에 대해 Copilot이 수정안을 제안·반영하는 기능을 2026년 6월 4일 공개함
- 대상 요금제는 Copilot Pro, Pro+, Max이며, 워크플로 실행 로그 페이지의 Fix with Copilot 버튼으로 시작 가능
- Copilot cloud agent가 실패 원인을 조사한 뒤 수정 내용을 사용자 브랜치에 직접 푸시하고, 완료 후 리뷰를 요청하는 방식
- 수정 작업은 GitHub의 클라우드 기반 개발 환경에서 수행되며, 로컬 환경 없이도 처리 가능
- 테스트 실패나 linter 오류처럼 반복적이고 시간이 드는 CI 문제를 Copilot에 넘길 수 있도록 설계됨
- 관련 사용 방법은 GitHub Docs의 Starting GitHub Copilot sessions 문서에서 확인 가능
원문: github.blog
AWS, SageMaker JumpStart에 Nemotron 3 Ultra 추가
- AWS가 6월 4일 Amazon SageMaker JumpStart에서 NVIDIA Nemotron 3 Ultra의 day-zero 배포 지원을 발표함
- 원클릭 방식으로 배포 가능하며, 모델 ID는 `huggingface-reasoning-nvidia-nemotron-3-ultra-550b-a55b-nvfp4`로 제공됨
- Nemotron 3 Ultra는 총 5,500억 파라미터·활성 550억 파라미터의 하이브리드 Transformer-Mamba MoE 구조와 최대 100만 토큰 컨텍스트를 지원함
- NVFP4 정밀도 기준으로 장시간 에이전트 워크플로 추론 속도 5배, 복잡한 에이전트 작업 비용 최대 30% 절감 수치를 제시함
- 에이전트 오케스트레이션, 코딩 에이전트, 딥리서치, 분기형 엔터프라이즈 자동화 같은 다단계 추론 업무를 주요 적용 사례로 제시함
- 배포 인스턴스는 ml.p5en.48xlarge, ml.p5.48xlarge, ml.g7e.48xlarge를 지원하며, 엔드포인트 실행 중에는 시간당 GPU 비용이 계속 발생함
- SageMaker Python SDK로 EULA 승인 후 바로 엔드포인트 배포와 추론 호출이 가능하고, 사용 종료 후 `delete_endpoint()`로 정리 필요함
원문: aws.amazon.com
NVIDIA·Microsoft, 윈도우용 로컬 AI 에이전트 도구 발표

- NVIDIA와 Microsoft가 COMPUTEX 2026·Microsoft Build 2026에서 윈도우 PC용 온디바이스 AI 에이전트 개발 도구를 공개함
- Microsoft eXecution Containers(MXC)로 코드 실행·파일 접근·작업 오케스트레이션에 격리와 정책 집행 계층을 제공함
- NVIDIA OpenShell은 MXC 기반 윈도우 런타임으로, 정책 생성·관리, 추론 라우팅, 개인정보 식별 정보 가림 기능을 함께 제공함
- OpenClaw와 Hermes Agent가 윈도우에서 MXC·OpenShell 기반 보안 강화를 추진 중이며, Hermes Agent는 네이티브 윈도우 지원과 데스크톱 앱도 추가됨
- RTX Spark 제품군은 데스크톱·노트북에 최대 1페타플롭 AI 성능과 최대 128GB 메모리를 제공하며, Microsoft는 Surface RTX Spark Dev Box 개발자 에디션을 준비 중임
- H Company의 Holo 3.1 모델은 컴퓨터 사용 모드에 맞춰 조정됐고 FP8 대비 메모리 사용량을 35% 낮춘 양자화 체크포인트를 포함함
- NVIDIA는 llama.cpp와 vLLM 최적화도 함께 공개했으며, 에이전트 추론 성능은 최대 2배, vLLM은 추가 최적화로 2.6배 향상을 제시함
Cloudflare, AI Gateway 지출 제한 베타 공개
- Cloudflare가 6월 5일 AI Gateway에 비용 기준 지출 제한 기능을 공개하고, ID 기반 예산·라우팅 기능은 비공개 베타로 발표함
- AI Gateway는 애플리케이션과 OpenAI·Anthropic·Google 등 모델 제공사 사이에서 요청을 중계하는 계층으로 동작함
- 새 지출 제한은 토큰 수가 아닌 달러 예산 기준으로 집계되며, 모델·제공사·사용자·팀·애플리케이션 단위로 범위를 설정 가능함
- 예산 기간은 일간·주간·월간과 고정형·롤링형을 지원하며, 누적 비용을 실시간으로 추적해 대시보드에서 필터링 가능함
- 한도 도달 시 기본값은 추가 요청 차단이며, Dynamic Routes 규칙으로 더 저렴한 대체 모델로 우회하도록 설정 가능함
- Cloudflare는 사내에서 Access의 JWT 신원 정보를 요청 메타데이터에 붙여 사용자별 비용, 팀별 사용량, 조직 단위 비용 배분을 추적 중이라고 설명함
- 지출 제한 기능은 모든 요금제의 AI Gateway 사용자에게 오픈 베타로 제공되며, 대시보드와 API에서 설정 가능함
조코레터는 개발자와 만드는 사람을 위해 AI, 소프트웨어, 제품 흐름을 한국어로 정리합니다.
#AWS #Cloudflare #GitHub #NVIDIA



