AI 에이전트 실험과 저정밀 학습 업데이트 #55

오늘의 레터
Anthropic, Project Fetch 2단계 결과 공개
- Anthropic이 6월 18일 공개한 Project Fetch 2단계에서 Claude Opus 4.7이 로보독 과제 일부를 인간 도움 없이 수행함
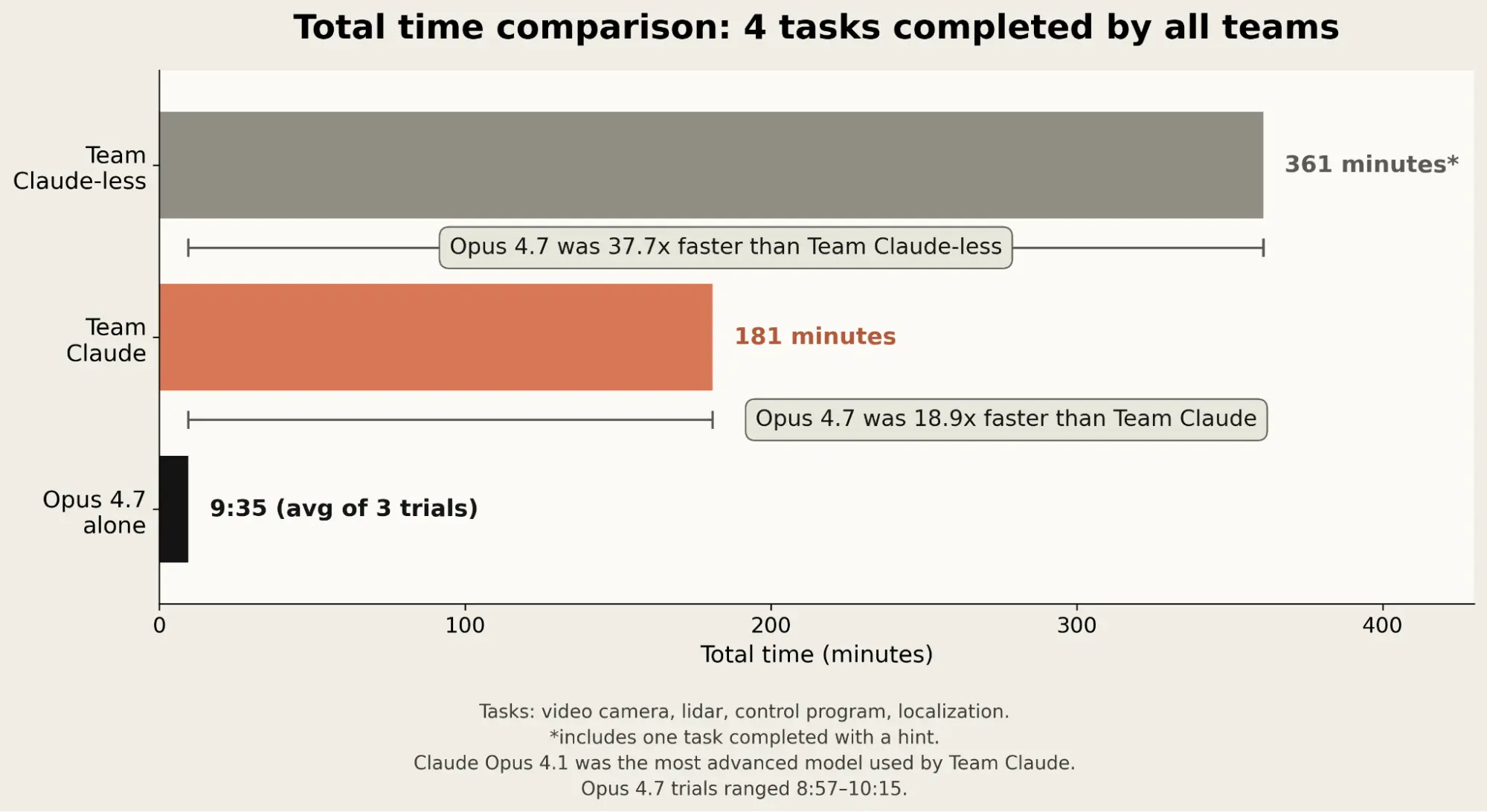
- 2025년 8월 1차 실험에서는 비전문가 직원 팀이 Claude Opus 4.1 지원 여부에 따라 경쟁했으며, 이번에는 Claude Code에서 adaptive thinking 최대 effort 설정으로 Opus 4.7을 3회 시험함
- 참가자들이 완료했던 과제 기준으로 Opus 4.7은 모든 완료 과제를 최소 10배 이상 빠르게 끝냈고, 전체 기준 가장 빠른 인간 팀보다 약 20배 빨랐다고 설명함
- 두 인간 팀이 모두 완료한 4개 과제 평균에서는 Claude 없는 팀 대비 37배 이상, Claude 사용 팀 대비 18배 이상 빨랐다고 제시함
- 센서 연결 경로 선택과 제어 코드 작성에서는 첫 시도부터 유효한 코드 비중이 높았고, Team Claude보다 거의 10배 적은 코드로 비슷하거나 더 나은 결과를 냄
- 다만 비치볼을 정밀하게 밀어 출발 지점으로 되돌리는 최종 회수 단계는 성공하지 못했고, 오래된 객체 탐지 알고리즘을 기본 선택하는 한계도 드러남
- Anthropic은 이번 진전이 로보틱스 전용 학습의 결과가 아니라 일반적인 모델 스케일링에서 나온 개선이라고 설명함
- 오프더셸프 물리 도구를 제한된 범위에서 다루는 초기 물리 에이전트 AI 단계에 가까워졌지만, 정밀 제어와 맞춤형 제어 정책 작성은 추가 연구가 필요하다고 평가함
원문: anthropic.com
참고: fourweekmba.com · forklog.com
NVIDIA, 트랜스포머 저정밀 학습 최적화 가이드 공개

- NVIDIA가 6월 16일 트랜스포머 기반 모델의 저정밀 학습 최적화 방법을 다룬 기술 블로그를 공개함
- Hopper와 Blackwell GPU의 FP8, NVFP4 지원을 바탕으로 GEMM 중심 학습 구간을 더 빠르고 저렴하게 처리하는 방식 설명
- 모델 설정과 배치 크기에서 실제 실행되는 M×K×N GEMM shape를 도출한 뒤, 정밀도별 벤치마크로 병목 구간을 확인하는 절차 제시
- 예시 구성은 50억 파라미터 모델 기준 hidden size 4096, intermediate size 16384, attention head 32, hidden layer 24, micro batch size 31, sequence length 512임
- 벤치마크 도구는 토큰 수 M=15872를 계산하고, 12개 GEMM shape를 추출해 BF16, FP8 계열, MXFP8, NVFP4 성능을 비교함
- Fprop, Dgrad, Wgrad를 각각 분리 측정해 행렬 비율 차이에 따른 커널 선택과 성능 편차를 함께 확인하도록 구성됨
- 기본 autocast 모드에서는 Transformer Engine이 각 GEMM 직전에 입력을 동적 양자화해, 양자화 비용과 커널 실행 시간을 함께 측정함
- shape별 차이도 커서 Attention output은 NVFP4 대 MXFP8이 1.05배 수준이지만, MLP down은 1.66배까지 올라 연산 종류별 편차가 있다고 설명함
원문: developer.nvidia.com
참고: tradekaizen.in
Sponsored · 조코헌트 · 와글와글 세포전 (자동)
🏆 조코헌트 TOP1 · 움직임과 포지셔닝으로 승부하는 군집 PvP 생존 게임

작은 세포 군집의 핵이 되어 영양 입자를 모으고, 레벨업으로 새 유닛을 합류시키며 살아남는 멀티플레이어 PvP 게임입니다.
전투는 자동으로 진행되고 플레이어는 이동·집결·도주 타이밍에 집중합니다. 엔드리스, 배틀로얄, 팀전까지 위치 선정과 판단이 곧 승패를 가르는 구조입니다.
조코레터는 개발자와 만드는 사람을 위해 AI, 소프트웨어, 제품 흐름을 한국어로 정리합니다.
#Anthropic #NVIDIA



