Copilot fixes, AI budgets, local agents #39
Today's Letter
- GitHub, Copilot fix flow for failing Actions expanded
- AWS adds NVIDIA Nemotron 3 Ultra to SageMaker JumpStart
- NVIDIA, Windows local agent stack expanded
- Cloudflare AI Gateway adds spend limits and identity budgets
GitHub, Copilot fix flow for failing Actions expanded
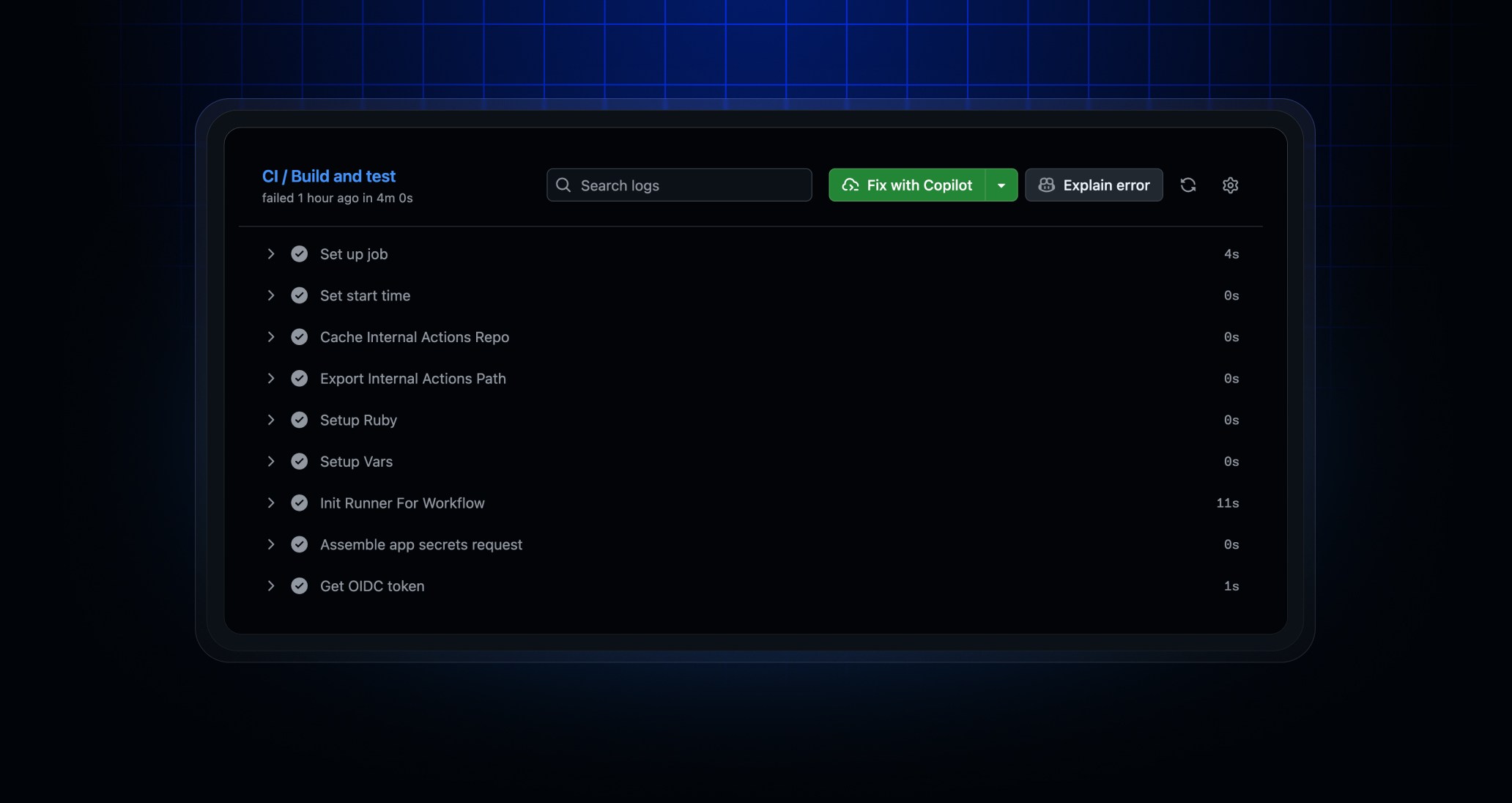
- GitHub added a one-click Fix with Copilot flow for failed GitHub Actions jobs on June 4, 2026
- The feature is now available to Copilot Pro, Pro+, and Max subscribers, according to the GitHub Changelog
- Users can trigger it from the workflow run logs page through a Fix with Copilot button
- GitHub says the Copilot cloud agent investigates the failure, prepares a fix, pushes it to the current branch, and tags the user for review
- The work runs in GitHub's cloud-based development environment rather than the local machine
- GitHub positions the feature for routine CI tasks such as broken tests and linter failures
- The update extends automated remediation inside Actions without requiring a separate manual debugging session
Source: github.blog
AWS adds NVIDIA Nemotron 3 Ultra to SageMaker JumpStart
- AWS announced day-zero availability of NVIDIA Nemotron 3 Ultra in Amazon SageMaker JumpStart on June 4, 2026
- The model is positioned for long-running agent workloads, with AWS stating 5x faster inference and up to 30% lower cost for agentic tasks
- Nemotron 3 Ultra uses a hybrid Transformer-Mamba mixture-of-experts architecture with 550 billion total parameters and 55 billion active parameters
- AWS lists support for up to 1 million tokens of context, text input and output, and NVFP4 precision for hosting efficiency
- Deployment is offered through SageMaker JumpStart with a one-click flow, or through the SageMaker Python SDK using the JumpStart model ID
- AWS highlights agent orchestrators, coding agents, deep research systems, and multi-step enterprise automation as target use cases
- Supported instance types include ml.p5en.48xlarge, ml.p5.48xlarge, and ml.g7e.48xlarge, with users needing sufficient SageMaker permissions and GPU quota
- AWS notes that deployment creates a billable SageMaker endpoint and says GPU instances such as ml.p5en.48xlarge can cost several dollars per hour until the endpoint is deleted
Source: aws.amazon.com
NVIDIA, Windows local agent stack expanded

- NVIDIA outlined new Windows-focused tools for local AI agents at COMPUTEX 2026 and Microsoft Build 2026, centered on security, on-device execution, and faster inference
- Microsoft introduced Microsoft eXecution Containers (MXC) as a policy and isolation layer for agents that execute code, access files, and orchestrate tasks on Windows
- NVIDIA said OpenShell is being brought to Windows on top of MXC, adding policy management, inference routing, and PII obfuscation for always-on autonomous agents
- NVIDIA named OpenClaw and Hermes Agent among the agent apps expected to use MXC and OpenShell to improve Windows security boundaries
- The RTX Spark family was presented as local agent hardware with 1 petaflop of AI performance and up to 128 GB of memory, aimed at running larger models alongside desktop workloads
- NVIDIA NemoClaw now supports NVIDIA client systems through Linux and Windows Subsystem for Linux, and now includes Hermes Agent as a runtime option
- Hermes Agent also released native Windows support with both a CLI and desktop app, intended to improve access to Windows apps, APIs, and local files
- NVIDIA also highlighted inference work in llama.cpp and vLLM, including 2x performance on Qwen 3.5 and 3.6 27B dense models, 1.6x on 35B MoE models in llama.cpp, and up to 2.6x gains in vLLM
Source: developer.nvidia.com
Cloudflare AI Gateway adds spend limits and identity budgets
- Cloudflare announced spend controls for AI Gateway on 2026-06-05, with dollar-based budgets that track cumulative model usage cost in real time.
- Limits can be scoped by model, provider, or custom attributes such as user, team, and application, with daily, weekly, monthly, fixed, or rolling windows.
- When a budget is reached, AI Gateway can block requests by default or reroute them to a fallback model through Dynamic Routes instead of stopping the workflow entirely.
- Spend limits are in open beta across all AI Gateway plans, and can be configured from the dashboard or through the API.
- Cloudflare also opened a closed beta for identity-driven budgets and policies by combining AI Gateway with Cloudflare Access and an existing identity provider.
- In that setup, authenticated user or service identity is attached to each request, enabling per-user attribution, team-level breakdowns, and policy enforcement by IdP group.
- Cloudflare said service tokens can give CI/CD pipelines and autonomous agents named identities, so budgets and model access can be controlled separately for each agent.
- AI Gateway already sits between applications and providers such as OpenAI, Anthropic, and Google, and also offers unified logging, response caching, rate limiting, and content guardrails.
Source: blog.cloudflare.com
Jocoletter curates AI, software, and product trends for developers and builders.
#AWS #Cloudflare #GitHub #NVIDIA



