Anthropic results and NVIDIA training guide #55

Today's Letter
- Anthropic, Project Fetch Phase Two results published
- NVIDIA, Low-Precision Transformer Training Guide
Anthropic, Project Fetch Phase Two results published
- Anthropic published Phase Two results for Project Fetch on June 18, 2026, testing Claude Opus 4.7 on robodog setup and autonomy tasks first run with human teams in August 2025
- In three trials with adaptive thinking at maximum effort in Claude Code, Opus 4.7 completed every task that at least one human team had finished at least ten times faster
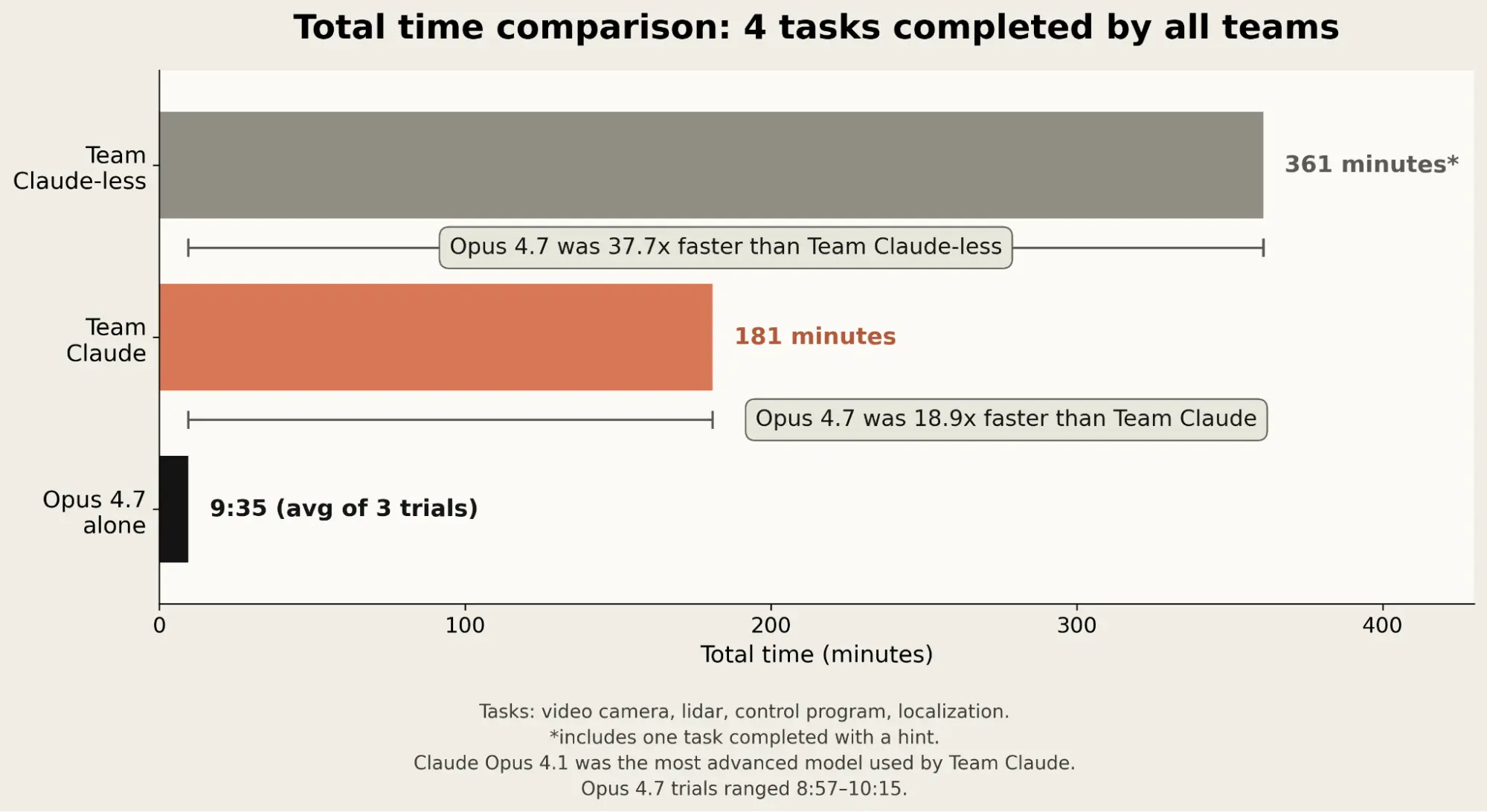
- Anthropic said the model was about 20 times faster than the fastest human team across tasks completed in the earlier experiment, and over four shared tasks it averaged more than 37 times faster than Team Claude-less and more than 18 times faster than Team Claude
- The researcher role was limited to connecting a laptop, entering the initial prompt, approving commands, and allowing progression to the next task
- Anthropic said Opus 4.7 often chose workable sensor interfaces quickly and produced effective code on the first try, while generating almost ten times less code than Team Claude in the earlier phase
- The model still defaulted to an outdated object detection algorithm in one case, but Anthropic said it worked around the issue and remained reliable on tasks within its capability envelope
- Claude did not complete the final beach-ball retrieval task autonomously, with Anthropic attributing the miss to weak closed-loop physical control and precise real-time adjustment
- Anthropic framed the result as evidence that general model scaling is improving practical use of off-the-shelf physical tools, while stopping short of claiming that robotics is solved
Source: anthropic.com
More: fourweekmba.com · forklog.com
NVIDIA, Low-Precision Transformer Training Guide

- NVIDIA published a tuning guide for low-precision transformer training on June 16, 2026.
- The post focuses on FP8 and NVFP4 support on Hopper and Blackwell GPUs.
- It argues transformer training time is dominated by GEMM workloads, not model config labels alone.
- The method converts model and batch settings into exact M×K×N GEMM shapes for benchmarking.
- NVIDIA Transformer Engine handles quantization and kernel dispatch for low-precision runs.
- The example uses a 5B-parameter model with hidden size 4096 and intermediate size 16384.
- The sample config also uses 32 attention heads, 24 layers, micro batch size 31, and sequence length 512.
- In autocast mode, the benchmark includes dynamic quantization cost with each GEMM measurement.
- The tool profiles Fprop, Dgrad, and Wgrad separately because aspect ratios affect kernel selection.
Source: developer.nvidia.com
More: tradekaizen.in
Jocoletter curates AI, software, and product trends for developers and builders.
#Anthropic #NVIDIA